January 10, 2021
, in technology
Machine learning and natural language processing – size does matter!
Natural language processing has made huge progress in the last few years, leading to massive advances in areas like machine translation and potentially useful tools for content authors and editors. How was it done?

Machine Learning and natural Language processing
Anyone who uses Google Translate from time to time will have been impressed by the recent improvement in the quality of its translations. The new performance owes its power to the advances in the area of machine learning known as Natural Language Processing (NLP).
Behind the quantum leap in quality there are two developments – the availability of huge collections of language samples that are used to train the neural networks and a smarter, more efficient training method known as Transformer.
Bigger is better
The size of the model and the size of the training sample turns out to make a big difference to the abilities of the trained network. An early model (way back in 2018!) Google’s BERT was trained on the whole English text of Wikipedia (2500 million words) and Googles Book Corpus (800 million). Shortly afterwards for T5 (The Text To Text Transformer) Google created C4 (Colossal Clean Crawled Corpus) that is two orders of magnitude larger than Wikipedia.
The current state-of-the art model - GPT 3 developed by OpenAI – consists of 175 billion parameters. Its language capabilities, from high-quality translation to poetry composition are correspondingly massive.
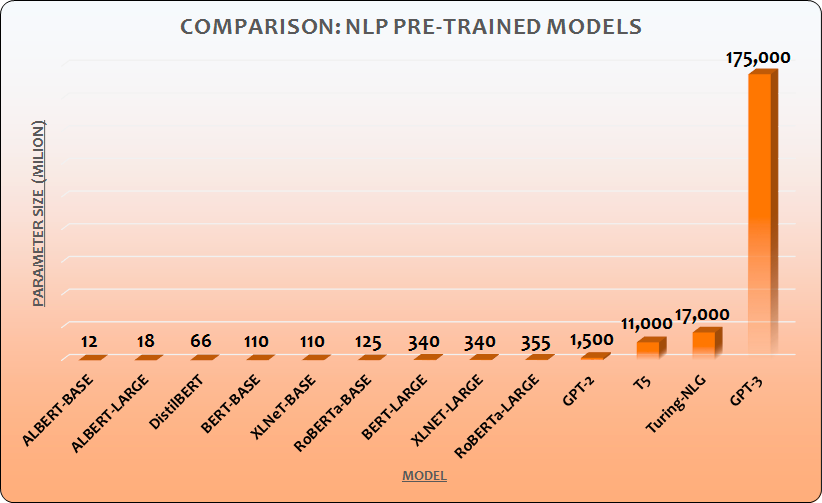
Diagram from: OpenAI GPT-3: Language Models are Few-Shot Learners
DIY training is faster
One of the advantages of using a large training corpus is that its size allows deep learning networks to develop advanced skills by training themselves. The pre-training is done by setting the networks simple tasks like picking sentences in the dataset, removing part of it and asking the network to predict the missing parts.
BERT is trained providing right and left sentence context, GPT is trained providing only left content and requiring the network to predict the final word (that’s why GPT is insanely good in text generation).
The assigning and scoring of these simple tasks can be entirely automated and carried out without need for supervision, vastly increasing the speed and volume of training that can be performed compared with networks needing human intervention in the training.
Next : But size isn’t everything!
In the next ML post we’ll be looking at the other development behind the dramatic improvement in NLP performance - the Transformer.
Read related article: