September 12, 2022
, in technology
The Rise of the Robot Readers
The quality and availability of the latest text-to-speech engines is opening up new application areas. For news publishers it is creating productive new opportunities for audience engagement.

Robot readers | Eidosmedia
The audio version of this article was created using the AI-driven BeyondWords speech engine integrated into the Eidosmedia editorial workspace. See end of article for details.
It used to be called ‘voice synthesis’ - now it’s Text-to-Speech (TTS). The application of AI to the generation of synthetic human speech has resulted in an explosion of speech engines offering increasingly realistic and natural renderings, and even the possibility to ‘clone’ the voices of real people.
This dramatic expansion in quality and ease of use has opened up several areas of potential application. No longer are robot readers relegated to reciting call directories to impatient people sitting on hold. Among the emerging applications for this new generation of realistic reading robots is that of turning news articles into ‘instant podcasts’.
‘Audio publishing’ has thus allowed publishers to create a new channel for consumers to access their content in situations such as driving or exercising in which reading the news is difficult or impossible. As well as presenting opportunities, these developments also have the potential for abuse.
What is text-to-speech and how does it work?
The conversion of written text to spoken language is not a simple matter of mapping syllables to sounds – especially in a non-phonetic language like English. Creating a natural sounding diction involves applying a large number of subtle rules (and their exceptions). The robotic quality of early speech synthesis resulted from the relative crudeness of the conversion algorithms being used. The application of AI has allowed far more sophisticated models to be generated from real speech samples, resulting in the natural-sounding speech patterns of today’s advanced TTS engines.
Take, for instance, Amazon’s Polly which, “uses advanced deep learning technologies to synthesize natural sounding human speech. With dozens of lifelike voices across a broad set of languages, you can build speech-enabled applications that work in many different countries.”
The key here is “lifelike.” Today, some text-to-speech engines can produce recordings that are essentially indistinguishable from real human voices. In fact, machines can now clone human voices — which raises some concerns.
The rise of the voice clones
Anyone who has ever listened to Samuel L. Jackson read the weather on Alexa may have found themselves wondering how Mr. Jackson had time to record all those weather reports. The simple answer is that he did not. Instead, he would have recorded a few hundred phrases specifically designed to let AI dissect and recreate his voice in a lifelike manner.
It’s all fun and games when it’s Samuel L. Jackson reading a weather report, but the possibilities for voice cloning are a bit more worrisome when you consider the potential for the technology to be abused. As Forbes reports, “A notable vendor has come across at least three cases of deepfake voice fraud since September 2019. Other firms are predicting that criminals will use AI tools to disrupt the operations of commercial enterprises and create confusion in business and customers' trust toward voice-biometric systems.” It’s clear that companies and consumers alike will need to be vigilant, but the potential of text-to-speech is too much for publishers to ignore.
Text-to-speech opportunities for publishers
Audio content is increasingly popular with audiences, but often requires voice talent, audio engineers, and more to produce — all of which can come with a high price tag. While you may not want AI producing in-depth, investigative podcasts, it can fill in the gaps to create more great audio content for the users who are hungry for it.
Many big-name publishers are already investing in audio strategies to help boost subscriptions, and text-to-speech is playing a big role in those strategies. The Washington Post launched text-to-speech audio articles across its platforms, while the Wall Street Journal added “Listen to this article,” followed by many of the leading daily and magazine publishers on both sides of the Atlantic.
BeyondWords - integrating TTS into the editorial workflow
Now that audio versions of news articles have entered the mainstream, publishers have been looking for ways of streamlining the production of this popular new format.
Eidosmedia has met this demand through a partnership with BeyondWords - a state-of-the-art text-to-speech engine that offers more than 500 AI voices across over 140 language locales as well as bespoke voice cloning.
BeyondWords delivers more natural-sounding speech than other TTS engines because it uses an extra layer of processing driven by a deep-learning model trained on large data sets. This automatically inserts Speech Synthesis Markup Language (SSML) tags to ensure correct pronunciation of names, dates, numerical data and other text strings that trip up conventional TTS engines.
Find out more about BeyondWords advanced NLP model .
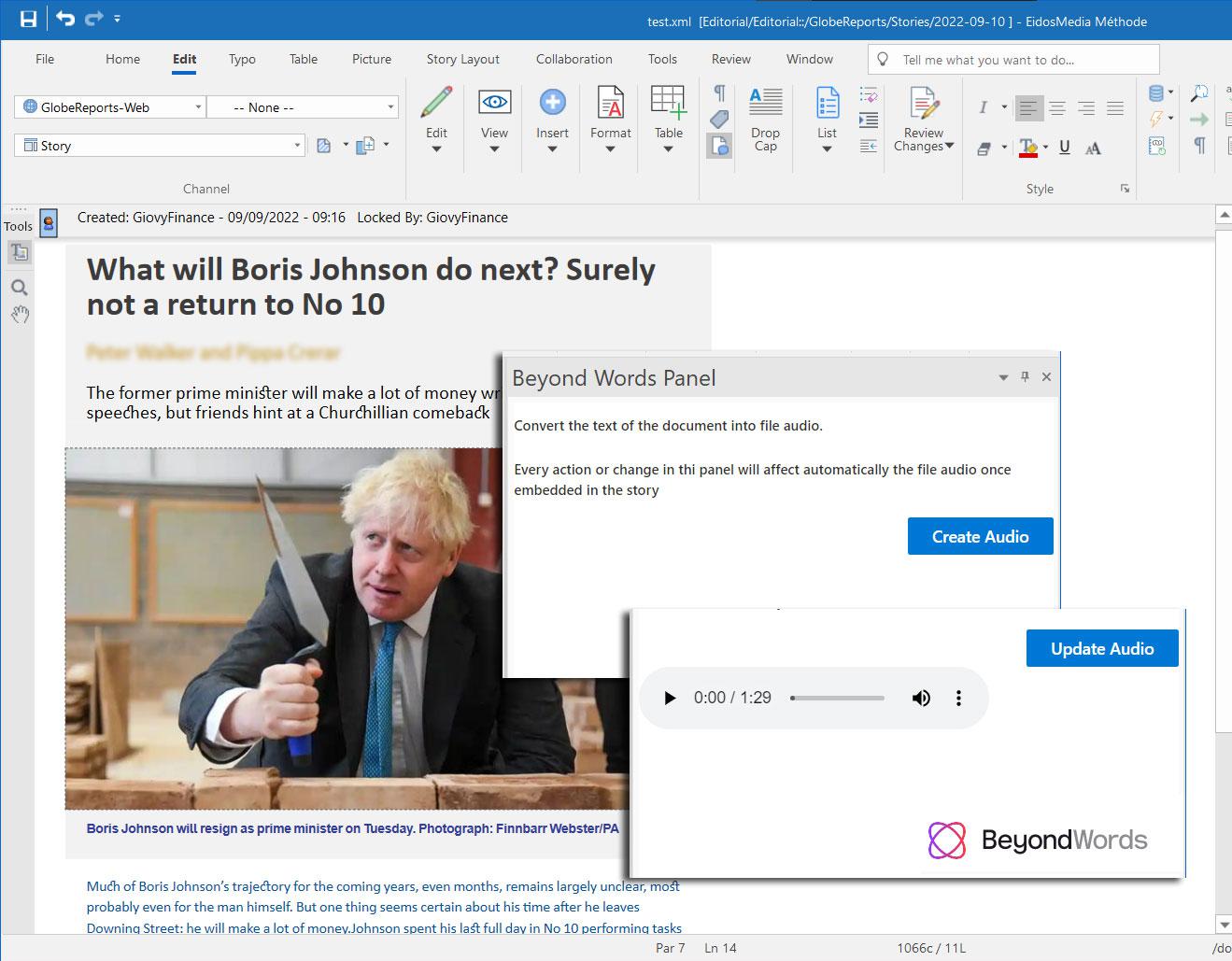
Using the audio UI
The BeyondWords ‘audio UI’ is integrated into the authoring workspace in the form of a side panel in the editor. It’s available both in the PC and mobile workspaces.
The conversion process is simplicity itself. Once the text is complete, the author generates the audio version by clicking in the side panel. The text is converted into an audio stream and the user can check it using the player in the same panel. If the text changes, the same button will generate the updated version. When the story is published, the audio version is accessible through an embedded player, configured according to customer preferences.
The BeyondWords speech engine was used to create the audio version embedded at the beginning of this article.