April 02, 2024
, in technology
What’s Missing In Generative AI?
Is the claim that generative AI could soon reach human levels of performance justified? Compared with ‘traditional’ AI, there appears to be a lot missing.

Generative AI | Eidosmedia
In the last post in this section we started to look at an ongoing debate in the AI community. The dispute is between those who see the current crop of generative AI models like ChatGPT as a step on the way to ‘real’ AGI (Artificial General Intelligence – the ‘Holy Grail’ of AI developers) and those who consider them a wrong turning or an ‘exit ramp’ which will never lead to human-level AI.
Although this is a theoretical question (for now) it has an important bearing on more practical questions about where AI research is going and how it should be regulated. This article will look at the evidence for each side of the debate and what can be concluded about the potential solutions and problems we can expect as the technology develops further.
Overcoming the limitations?
Most people who have followed AI developments over the last year will be aware that the large language models driving applications like ChatGPT have limitations. Perhaps the most well-known of these is the tendency to ‘hallucinate’ or make up stuff that sounds plausible but has no basis in reality. Other weaknesses include their performance on math problems or logical reasoning tasks, where they regularly fail to score 100% and often score lower than a typical human subject.
The developers of these models have naturally tried to improve performance through improved training programs or prompt engineering and have had some success reducing the incidence of incorrect or offensive output and improving math ability (but not yet to 100%).
The assumption is that incremental improvements to the models will sooner or later lead to the full achievement of AGI at or above human levels:
“The most important parts of AGI have already been achieved by the current generation of advanced AI large language models.”
is the claim in a recent article by AI researchers working for Google.
Is the model fundamentally flawed?
But those unconvinced by this argument deny that the weaknesses in current models can be remedied by better training or prompt development because they are due to fundamental flaws in the basic approach.
They argue that such models will never be able to function at the level of human subjects because they are missing critical components that are indispensable for AI constructs to operate at a fully human level.
So what’s missing?
The first missing component that critics point to is something that we can call ‘a model of the world’.
Human intelligence is based on such a model. Although human cognition and cognitive development are not yet fully understood, it’s clear that we have a representation of the world ‘inside our heads’ that is continuously being modified by information from our senses and sources of information mediated by language.
We use this model to plan actions and, where it proves incorrect or incomplete, we update it.
Modelling our world model
The earliest attempts to create artificially intelligent systems were based precisely on this model of human cognition and intelligence. They attempted to create a digital representation of the world inside a computer system, that could be used as a basis for interactions with human subjects.
An early example of this experimental AI were the ‘block worlds’ created by researchers like Terry Winograd in the 60s. They consisted of a simulated 3D space with colored solids in it. The computer could receive natural-language instructions like ‘Put the red cone on top of the blue cube’ and would carry them out in the simulated space. It could also answer questions like: “Is the red cylinder behind the green sphere?”.
Other early ‘machine learning’ examples included computers that could play chequers, solve mazes, plan deliveries etc.
Although they were severely limited at first by the modest computing power available and periodic lack of funding from disappointed governments, these kinds of model gradually became more powerful. Some evolved into ‘expert systems’ that could answer detailed questions about specialized areas of knowledge. A major milestone for this kind of rules-based system came in 1997 when IBM’s Deep Blue beat the reigning chess world champion Gary Kasparov.
What all of these programs had in common was a simulated model of a part of the world and rules for manipulating the elements of the model. In the case of the chess computer the ‘world’ consists of the chess board and the rules of the game. An industrial robot’s world consists of the components it manipulates and the rules for their combination.
GOFAI – Good Old-Fashioned AI
These systems are all examples of a ‘traditional’ approach to AI which nowadays is known by a variety of names: ‘rules-based’ AI or ‘symbolic’ AI – or more facetiously, GOFAI – Good Old-Fashioned AI.
What the systems have in common is the attempt to replicate the process by which humans learn about the world – receiving information through the senses and building a model of the world ‘inside the head.’
Looking towards AGI
An important point to note about this form of AI is that each system is focused on one specific domain of activity and cannot be used outside it. Chess computers cannot do math and industrial robots do not clean the home. In this context, the ultimate goal of AI research was the creation of ‘general’ intelligence – a system that can turn its hand to any kind of task that a human can perform.
The emergence of the neural network
But these kinds of rule-based AIs were not the predecessors of the generative AI models whose spectacular performance has surprised and alarmed the world over the last year or so. These systems have their origin in another technology that also has its roots in the Sixties and, after a slow start, was destined to lead to the generative AI models of today – the artificial neural network.
Machine learning
A neural network simulates within a computer the arrangements of nerve cells in a biological brain. Early networks consisted of three layers - an input layer, an intermediate layer and an output layer.
The networks were trained by repeatedly presenting an input (for example, the digital image of a hand-written numeral) and evaluating the output (in this case the numerical value of the number presented).
The training routine automatically adjusts the connections between the neurons to minimize the error between the output answer and the correct value. After multiple iterations, the network is able to correctly identify hand-written numerals with accuracy approaching 100%.
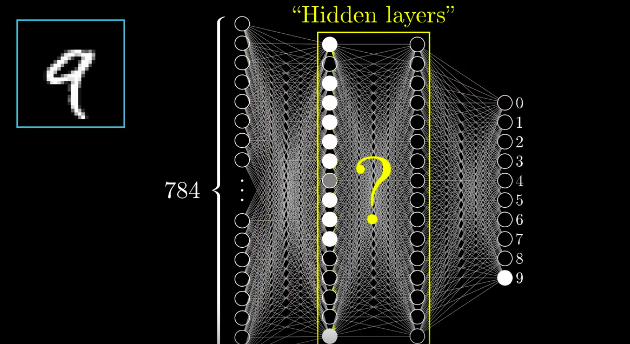
Source: Machine Learning: How Does a Neural Network Recognize Handwritten Digits?
‘Deep’ learning
From early examples like these, neural networks became larger and ‘deeper’ - with more intermediate layers between the input and output - allowing them to tackle more complex problems.
The approach – which is more correctly termed ‘machine learning’ (ML) rather than AI – turned out to be particularly suitable for tasks that are difficult to break down into explicit rules or algorithms. They include things like speech recognition and language translation, as well as many analytical processes from financial modelling to complex molecular structures where there are too many variables for a rules-based approach.
Reproducing the brain – content vs structure
Comparing this approach with traditional AI we could say that both are attempts to reproduce the workings of the human brain. But while traditional methods aim to replicate its content – the concepts and rules that make up knowledge of the world - neural networks attempt to reproduce its structure – the complex webs of neurons underlying our cognitive processes.
The ‘black box’ problem
One consequence of the structure of neural networks is that the activity in the inner layers between the input and the output is hidden. The simulated neurons make and break connections with each other as they process their training data, but this activity and the resultant network of connections is not observable – it behaves like a ‘black box’.
This means that when the network carries out a task, unlike a rules-based system whose workings may be tracked by inspecting the system logs, it is impossible to discover how the network arrived at a particular result. If the result is erroneous or undesirable, there is no direct way to correct the working of the model.
This may have important consequences for the usability of the network. Where the consequences of a decision may be critical, such as a medical diagnosis or a legal decision, the application of neural networks needs to be done with caution, because the cause of faulty performances cannot be traced or rectified.
The GPT breakthrough
Fast forward to the last decade and neural network technology has taken advantage of the availability of powerful computing resources (including specialized graphic processing units - GPUs - which turned out to be ideal for the massive parallel processing needed.)
At the same time, the ‘Transformer’ technique developed by Google researchers in 2017, together with training on huge language corpuses, led to the quantum leap in performance represented by the arrival of large language models like ChatGPT.
Seduced by generality
Looked at in the context of traditional AI systems, we may be struck by how generalizable the performance of the latest large language models is. They seem to be able to operate across multiple language domains and adapt their output to a vast range of purposes and contexts. In this sense it is understandable that some AI practitioners have hailed them as precursors to the full achievement of AGI.
A model raised in ‘solitary confinement’
But, from the same perspective, it is striking how much is missing. In fact, an LLM is like a human being whose entire life experience consists of sitting in a closed room, reading or listening to a vast corpus of text, with no direct experience of the world or action within it. They have no representation of the world, independently of the language samples used to train the system. There are no rules or generalizations about how things in the world behave or can be acted upon, apart from what is stated in the corpus of training data.
Such an unfortunate being would perhaps be capable of impressive linguistic feats, but having no direct contact with the things or people referred to in the corpus, it would be difficult to claim that they even understood their training in any meaningful sense.
Locked into language
Seen in this way, the weaknesses of LLMs are easy to understand. Lacking any world knowledge independent of the statements in their training data, they are unable to verify the truth of the language strings they produce. Not having learnt the rules of mathematics or logical reasoning, they are forced to provide the most ‘probable’ solutions to problems – which may not be the correct ones.
In a paper entitled AI’s challenge of understanding the world, AI researcher Melanie Mitchell identifies this lack as a fundamental obstacle to regarding LLMs as candidates for AGI:
Current AI systems seem to be lacking a crucial aspect of human intelligence: rich internal models of the world.
She goes on:
The problem of acquiring “world models” has been a focus of AI research for many decades. Researchers have experimented with many methods for either manually programming such models or for trying to get machines to learn them from data or experience…
However, LLMs and other generative AI systems are a different ballgame. No one has programmed any world models, nor are these systems explicitly trained to learn them.
Can GenAI models be extended?
We’ve seen that the current AI models based on enormous neural networks are limited in their performance because they lack some of the elements that have been fundamental to the working of more traditional AI models: a model of the world, hard-wired logical and mathematical capabilities.
But the question remains: could LLMs acquire these things – either through their own learning processes or through ‘add-ons’ created to provide knowledge of the world and reliable reasoning capabilities?
The next post will look at the possibilities of extending generative AI models and the results that have been obtained in that direction.
Meanwhile – generative AI does useful work
While the theoretical debate on the exact nature and potential of generative AI continues, these models are significantly improving productivity in sectors from news media to financial services.
By taking care of complex or routine tasks that take up the time of authors and editors, the models free up human resources to concentrate on adding value and building customer engagement.
Find out how generative AI technology is enhancing productivity in the news-media sector.
