September 22, 2025
, in technology
Will GenAI reasoning ever be reliable?
One of the more surprising weaknesses of generative AI (GenAI) models is their poor performance on reasoning tasks. Considerable effort has been put into improving it – but it may be hitting a wall.

GenAI and Reasoning: Can Large Language Models Truly Think? | Eidosmedia
Exploring the limits of LLMs
In the last post in this series What’s Missing In Generative AI? we looked at the elements that appear to be missing in today’s generative AI models and asked if the models could be extended to include them.
One of these missing ingredients was ‘reasoning’ – the ability to solve logical and mathematical problems and also to handle rule-based tasks like writing computer code. In this post we’ll look at the difficulties that GenAI models have had with these kinds of operations and the attempts made to overcome them.
AI deductive reasoning - sub-human performances
Early users of large language models (LLMs) were surprised at how mediocre they were at logical or mathematical deduction – after all, weren’t computers supposed to be fast and accurate at these kinds of operations? And yet they often made elementary errors and turned in performances inferior to that of a typical human subject.
GenAI reasoning - poor concentration
LLMs turn out to be easily distracted. A recent paper by Apple researchers revealed that a simple fruit addition problem (“Oliver picks 44 kiwis on Friday …”) was easily solved by most models. But the addition of a piece of irrelevant information (“… five of them were a bit smaller than average”) completely threw most of them. The authors commented: “… the majority of models fail to ignore these statements and blindly convert them into operations, leading to mistakes.”
To be fair, this doesn’t necessarily cast doubt on the models’ reasoning powers in themselves, but it does show weakness in framing the problem.
Reliance on familiarity
More serious is the observation that GenAI models perform better on commonplace problems - the kind that they are likely to have met in their training data. In fact, so large are the language corpuses used to train the latest models, they are almost certain to include examples of any published mathematical or logical problem.
To test this idea, studies have been made in which models were given new versions of problems in which names and quantities were changed, leaving the logical structure of the problem the same. Human subjects tested on the new versions did as well as on the original problems. The performance of the LLMs, however, declined sharply on the unfamiliar versions, suggesting that, unlike the human subjects, they are not using deductive processes but rather, relying on familiar examples from their training data.
A dramatic example of this reliance is the benchmarking test reported in the TechCrunch article Why is ChatGPT so bad at math? involving the multiplication of two numbers.
For numbers up to 3 figures, performance is near 100%, but accuracy starts to drop off when multiplying 4-digit numbers, falling to zero for five digits and beyond.
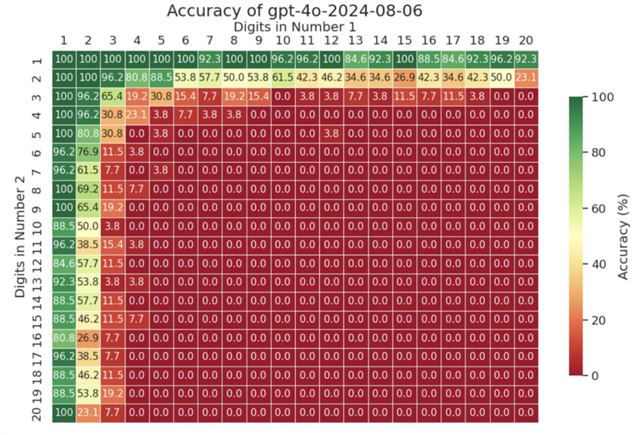
ALT text – GenAI mathematical benchmarking
Benchmarking by Yuntian Deng, University of Waterloo
This is a strong indication that the model’s ability to perform a multiplication depends on the presence of an example in the training data. As soon as the probability of this falls below a certain level, the model is incapable of performing the operation correctly – a clear sign that its success on smaller numbers is replication rather than calculation in the true sense.
Why is GenAI so bad at reasoning?
The kind of limitations we’ve looked at become easier to understand if we look at the way the models are trained. The mechanism is a fairly simple one as described in the earlier post How ChatGPT Really Works:
-
"A neural network, capable of ‘learning’, is presented with the first part of a sentence and must supply the next word. The ‘correct’ answer is then revealed and the network adjusts its parameters accordingly. After training on billions of sentences from a huge corpus of texts, such as Wikipedia or the entire internet, the model becomes very good at predicting the continuation of sentences."
This process creates an enormous quantity of information about the connections between words in the training data, allowing the impressive linguistic feats that have become familiar to users of GenAI models. But when this statistical information is applied to a task where there is only one correct answer, the model, not having hard-coded deductive abilities, can only supply the most likely solution – which is not necessarily the correct one. The further the problem lies from the examples the model has digested in its training data, the less likely it is to solve it successfully.
Pattern-matching is not enough
In effect, when tackling a deductive problem, an LLM is engaged in ‘pattern-matching’ - and if a suitable pattern is not found, or there is interference from irrelevant information, it will fail to solve the problem.
It’s important to note that this approach is very different from that used by human subjects (or dedicated logic applications). Human reasoning involves the application of general rules to specific problems or the extraction of general principles from specific examples.
General rules and principles are independent of any particular example – once a subject has mastered arithmetical operations, for example, they can apply them to an indefinite number of novel problems even if they are different from the examples they were trained on.
GenAI models do not enjoy this independence. Instead of reasoning from general principles they rely on finding similar examples in their training data. While training sets are typically very large, they cannot include every permutation the model is likely to encounter, resulting in a residue of unreliability that is difficult to remedy.
Chain of Thought – a step by step solution
Once the weakness in deductive reasoning had been noted by developers the search was on for a way of reducing or eliminating entirely this source of unreliability.
The most successful of these was the ‘chain of thought’ approach first introduced in a study by Google researchers who noted that the technique “significantly improves the ability of large language models to perform complex reasoning.”
How does it work? Normally when a commercial LLM is given a task, the prompt is designed to elicit a single response, representing the model’s final reply to the user.
The Chain of Thought (CoT) technique uses a more complex prompt in which the model is invited to ‘show its working’ by listing the steps it has taken in arriving at a solution. This may be done by giving the model a few examples of a similar step-by-step deduction or simply through an instruction: “Let’s work step-by-step”.
An example from the cited paper shows an LLM arriving at an incorrect solution with a conventional prompt:
The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
The answer is 27*.
Presented with the same problem using a CoT prompt, the model delivers the correct answer:
The cafeteria had 23 apples originally.
They used 20 to make lunch. So they had 23 - 20 = 3.
They bought 6 more apples, so they have 3 + 6 = 9.
The answer is 9
The approach had two advantages – firstly it improved performance on complex reasoning tasks – often allowing smaller models to beat the performance of larger models using a normal prompt technique.
Secondly, the output of the model appeared to contain all the intermediate reasoning leading to the final response. If this was incorrect, it allowed some insight into where the reasoning had gone wrong and this could be fed back into the model, improving its performance on subsequent tasks.
On the other hand, the need for extra ‘compute’ during the delivery of the response made CoT operations both slower and more costly in terms of processing power.
Chain-of-Thought is not cheap
Following the early success of the approach it was widely adopted with many subsequent releases of GenAI models (such as OpenAI o3 and OpenAI o4) specifically designed to optimize the use of CoT prompting. Improvements in performance on deductive and mathematical reasoning were often impressive.
Against this, the extra ‘compute’ required by the CoT process pushed up the cost of responses significantly. OpenAIo3, unveiled at the end of 2024, was initially estimated to cost a minimum of $20 per request to a maximum of $1500 for complex problem-solving – obviously impractical for most users.
Off to the Reasoning Races – benchmarking Chain-of-Thought
At the same time there was a need to benchmark these advances in deductive power and a number of test batteries were devised. Care was naturally taken that the problems posed were completely novel in order to prevent the familiarity effect caused by models having encountered similar examples in their training data.
Performance on these dedicated benchmarks became an important marketing tool for AI companies, sometimes resulting in debatable practices to maximize test results. The model OpenAI o3, mentioned above, used intensive pre-training and test-time computing to achieve over 80% on the demanding ARC-AGI test battery. The cost was estimated to be around $5,000 for each of the 100 tasks in the test – obviously not reflecting any real-life use of the model. In a podcast Microsoft CEO Satya Nadella dismissed the claims surrounding this kind of activity as "nonsensical benchmark hacking".
In spite of these drawbacks, CoT approaches have demonstrably improved the performance of LLMs and the current releases of most models incorporate some kind of reasoning stage and many call themselves LRMs – Large Reasoning Models.
Problem solved? Not quite
While LRMs are now the best-of-breed of the GenAI engines in terms of reliability on deductive tasks, a number of issues have emerged over the last few months that suggest that the problem is far from solved.
The first concerns a residue of problem types that continue to trip them up. The notorious ‘Alice in Wonderland’ (AIW) problem is relatively easily solved by humans, while regularly flunked by LRMs:
"Alice has 1 brother and she also has 2 sisters. How many sisters does Alice’s brother have?".
A systematic study with leading models has shown that “AIW causes collapse of reasoning in most state-of-the-art LLMs.”
The authors report that “most of the models suffer a severe breakdown, with many not being able to deliver a single correct response.”
Another class of problems that current LRMs completely fail at is the Towers of Hanoi game involving transferring disks from one peg to another according to simple rules.
A recent study by Apple researchers showed that leading LRMs failed to solve the problem with more than 7 disks, although most human subjects can manage it. Algorithms for solving it were developed as early as 1957 and are available on the web. Even when provided with the algorithm the models could not complete the task.
These results reflect badly on the ability of LRMs to carry out extended deductive processes, although the authors conceded that "puzzle environments represent a narrow slice of reasoning tasks and may not capture the diversity of real-world or knowledge-intensive reasoning problems."
What are they really thinking?
The most recent source of concern about the reasoning ability of GenAI models comes from studies that have sought to find out what is really going on when an LLM carries out a stepwise deductive process. They have revealed that the actual path a model uses to arrive at a solution may be very different from the step-by-step working that it displays to the user.
Looking inside the model
It’s generally accepted that the internal workings of the neural networks that drive LLMs are not observable, being a kind of ‘black box’. Nevertheless, a group of researchers from Anthropic have developed tools that enable them to reconstruct the conceptual structures involved in performing a given task and the interactions between them. They applied these tools to one of Anthropic’s LLMs while it was performing a range of tasks from a simple deduction to rhyme composition, arithmetic and medical diagnosis.
The study reveals that the actual process leading to a response is usually far more complex than the steps reported in the CoT reasoning. They often involved parallel mechanisms and even conflict between different representations. They reveal elements of planning and even ‘deception’ in which the model works towards a predetermined answer, while concealing this fact in its reported reasoning – something which should sound an alarm bell regarding the abuse of such models.
The results indicate that even when an LLM is showing its working in response to a CoT prompt, the actual processes leading to the solution may be quite different from the steps displayed to the user.
Chain-of-thought reasoning ‘a mirage’?
Another recent research project in this area attempts to measure the dependency of CoT reasoning on the patterns in the training data. The paper Is Chain-of-Thought Reasoning of LLMs a Mirage? describes how, by training an LLM from scratch, researchers were able to tightly control the content of its training data. They were then able to show that the model’s subsequent reasoning performance on problems was closely correlated with the degree of similarity between the problem and the examples it had been trained on ("in-distribution data"):
“Our findings reveal that CoT reasoning works effectively when applied to in-distribution or near in-distribution data but becomes fragile and prone to failure even under moderate distribution shifts.”
They conclude:
“The results suggest that what appears to be structured reasoning can be a mirage, emerging from memorized or interpolated patterns in the training data rather than logical inference.”
The practical implication is that CoT reasoning may be reliable when applied to problems similar to the content the model has been trained on but should not be relied upon when used in less familiar domains.
So - can LLMs reason or not?
Developments over the last year or so have shown that the reasoning power of LLMs can be improved and chain-of-thought techniques have led to greater reliability in their deductive processes – albeit at the price of higher processing costs and longer response times.
But it is now becoming clear that the kind of ‘reasoning’ involved is strongly dependent on the content of its training data, often bears little resemblance to the underlying processes being used by the models and, for some kinds of problem, is incapable of delivering accurate responses.
But this should not surprise us, given the nature of the training that underlies these models. Without any hard-coded mathematical or logical capabilities, they remain vast collections of statistical data. Their deductions are based on pattern-matching, the identification of the most probable answer to any problem, not the correct one.
Clever prompt engineering may weed out the most erratic responses but, given the statistical nature of the knowledge source, the final output will always be, to some extent, unreliable.
The last word?
Interestingly, a current LLM (ChatGPT 5) is quite clear about the limitations of its underlying technology.
Asked if GenAI reasoning will ever overcome its reliability problems, it concludes:
So, Will Generative AI Ever Be Fully Reliable?
No, at least not entirely.
- Hallucinations are a mathematical inevitability in probabilistic generative systems.
- Understanding remains shallow—mirroring patterns rather than genuinely grasping meaning.
- Risks like model collapse persist with recursive reliance on AI-generated data.
At the risk of anthropomorphizing the model, we could say that it can’t be accused of lacking self-awareness.
In the next post in this series we will look at the other missing element in GenAI – the ‘world-model’ and the latest attempts to extend AI engines in this direction.
Meanwhile GenAI does useful work in the newsroom
Where AI models are already adding real value is by taking care of routine, time-consuming tasks, freeing authors and editors to concentrate on creating engaging content. The latest AI assistants can 'package' a story in a few seconds to create headlines, summaries, subheadings, SEO elements and social posts.
The arrival of the ProActions framework now allows users to create their own AI tools from multiple models, optimizing their integration into the workspace and maximizing productivity. One recent development generates the entire suite of story elements detailed above with a single click, significantly cutting time-to-market for breaking news stories.
Find out more about the ProActions AI framework.
For print publishers, the layout of print pages is still a major cost item. Eidosmedia customers in Germany are now using an integrated AI engine to cut the layout for a print edition from several hours to a few minutes.
Find out more about AI print pagination .
