February 02, 2026
, in technology
Beyond GenAI - a world model?
Generative AI’s continuing problems of hallucination and unreliability are increasingly attributed to the lack of a ‘world model’. What does this mean and why does it matter?

Beyond GenAI: Can World Models Fix AI Hallucinations?
In an earlier post in this series we asked What’s Missing In GenAI? with the aim of identifying the gaps between the performance of current large language models (LLMs) and that needed to reach human-level intelligence (commonly called AGI).
Today’s leading or ‘frontier’ models continue to show serious weakness in two main areas. The first is in deductive and mathematical reasoning where LLMs often prove unreliable and inferior in performance to human subjects. Why this should be and the attempts made to mitigate it are the subject of our last post Will GenAI reasoning ever be reliable? .
The second missing element is something that we might call a ‘world model’. In this post we look at what a world model consists of and why its lack penalizes the current generation of language-based AIs.
Modeling our knowledge of the world
Although human cognition is not completely understood, it is clear that humans have a representation of the world ‘inside the head’ which is continuously updated by information from our senses. We use this model to plan actions and, where it proves incorrect or incomplete, we update it.
Large language models, on the other hand, have no knowledge of the world in this sense. They have only a body of statistics about the relationships between words in a massive corpus of what people have said or written about the world.
This is one reason for the continuing tendency of LLM’s to ‘hallucinate’ - they have no independent way of checking the truth or validity of the phrases they generate outside of the language samples in their training data. As we observed in the earlier post:
“… an LLM is like a human being whose entire life experience consists of sitting in a closed room, reading or listening to a vast corpus of text, with no direct experience of the world or action within it.
They have no representation of the world, independently of the language samples used to train them. There are no rules or generalizations about how things in the world behave or can be acted upon, apart from what is contained in the corpus of training data.”
Maybe size matters
It was the hope of early developers of LLMs that this limitation could be overcome through sheer size and and, accordingly, they trained their models on ever-increasing amounts of training data.
Reliability did improve – at first. But, as training corpuses have grown larger and absorbed almost the whole of the world’s online language resources, this approach seems to have hit a wall of diminishing returns: ‘hallucinations’ remain a significant problem.
Perhaps a world model could ‘emerge’
Another early hope was that models could spontaneously extract a coherent view of the world from their massive training data.
Several studies have explored this possibility. One of the most conclusive involved training an AI model to navigate in Manhattan by digesting sequences of taxi journeys (‘left, second right, next right …’). Once trained, the model could provide almost perfect route navigation to any destination in the area, as if it had built a fully accurate street map.
But when the developers examined the implicit map the model had built, it turns out to be extremely bizarre, containing many impossible routes and connections. In addition, introducing a few road closures completely degraded the model’s navigation performance, revealing that its understanding of the city plan was fragile and incoherent.
A model of the world had emerged from the training data – but it was very far from being accurate.
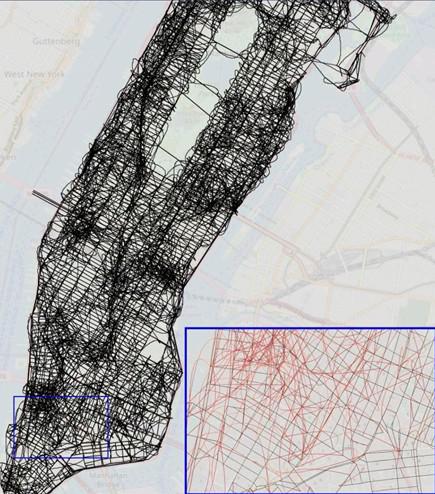
Illustration from the paper ‘Evaluating the World Model Implicit in a Generative Model’ by Keyon Vafa, Justin Y. Chen, Ashesh Rambachan, Jon Kleinberg and Sendhil Mullainathan.
Deviant geographies
The lack of a knowledge of the world outside of that contained in the training data becomes most acute when LLMs are asked to perform tasks in which accuracy is particularly critical. Examples of this are the creation of a geographical map, say of cities and states in North America.
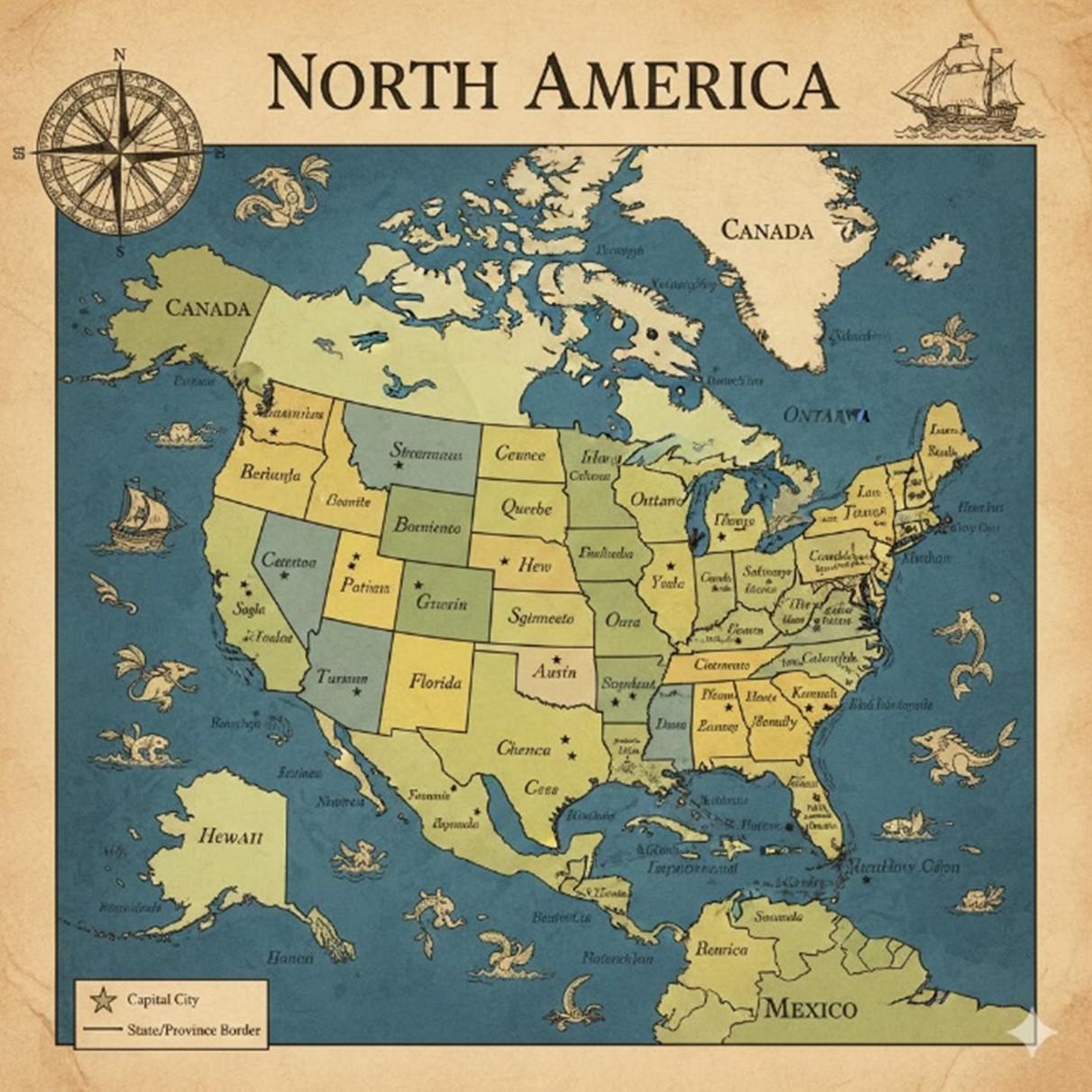
Map generated by Gemini 3 on 21.12.2025.
Prompt: Please create a map of North America with states and their capital cities labelled clearly.
This typically results in some very peculiar geographies, with placenames invented or misspelt, cities and states widely distant from their real locations. The reason for this is that, although there may be many references to the location of places in the training corpus, they are not sufficiently numerous or precise to allow an exact mapping of their positions.
A ‘fuzzy’ view of the world
It’s becoming clear that generative AI models do not develop reliable models of the world, however much training data they have digested. This is due in part to the limits of the input: the sentences in the training data cannot contain descriptions of every possible permutation of objects in the world. At the same time, the mechanism that powers generative models – statistical pattern matching – is intrinsically oriented towards delivering the most likely response – not necessarily the correct one.
Although there are ways of mitigating or reducing the errors that arise from this ‘fuzzy’ operational model, a residue of unreliability will always remain. This limits the usefulness of AI models, often requiring that there always be a ‘human in the loop’ and severely limiting their deployment in critical areas like legal, medical or financial applications.
Back to the old models?
As it has become clearer that the unreliability of LLMs is an intrinsic characteristic of the model that can be reduced but not eliminated, there has been growing interest in AI solutions based, not upon language corpuses, but on world models.
Ironically, this takes the AI field back to a rival approach to artificial intelligence that the recent success of LLMs has thrust into the background.
This approach is known by a number of names: ‘rules-based’ AI or ‘symbolic’ AI – or more facetiously, GOFAI – Good Old-Fashioned AI.
These systems consist of a simulated model of the world and rules for manipulating the elements of the model. Simple examples are the models that drive chess computers or robot vacuum cleaners like the Roomba.
In the case of the chess computer the ‘world’ consists of the chess board and the rules of the game. The Roomba’s world consists of some simple rules for movement and the map it builds up of the rooms during its first attempts to navigate the house.

What use is a world model? Prediction and planning
Having a world model allows an AI to carry out two key activities that are essential for acting in the world: prediction and planning.
In the prediction mode the model uses what it knows about the world to foresee the effect of a possible action. “If I continue in this direction, I will hit an obstacle,” “If I move my knight my queen will be vulnerable.”
In the planning mode, the model identifies a series of actions which it predicts will lead to a desired end-state of the world model: “Checkmate,” “Kitchen floor clean.”
In the second part of this post we will look at how the principles behind these simple examples of 'physical AI' can be extended to building a more complete world model for advanced AI purposes.
What 'knowledge' would such a model need to contain? How could it be learnt? In the next post we'll explore the answers to these questions.
Click to read the next post: How could AI get a real world model?
Meanwhile GenAI does useful work in the newsroom
In the creation and delivery of news content, AI assistants are adding value by taking care of routine, time-consuming tasks, freeing authors and editors to concentrate on creating engaging content. The latest AI assistants can 'package' a story in a few seconds to create headlines, summaries, subheadings, SEO elements and social posts.
The arrival of the ProActions framework now allows users to create their own AI tools from multiple models, optimizing their integration into the workspace and maximizing productivity. One recent development generates the entire suite of story elements detailed above with a single click, significantly cutting time-to-market for breaking news stories.
Find out more about the ProActions AI framework.
For print publishers, the layout of print pages is still a major cost item. Eidosmedia customers in Germany are now using an integrated AI engine to cut the layout for a print edition from several hours to a few minutes.
Find out more about AI print pagination.
